


700億パラメータを持つ日本語LLM「Eliza Japanese Llama 2 7b」について紹介していきたいと思います。
これまで国産の言語モデルは何個か出てきていましたが、あまり良いものがありませんでした。グローバルなGPT-4やGemini、Claudeなどと比べると、精度が低くて見劣りしていました。
個人的にはわざわざ国産のAIを使う必要性を感じなかったんですよね。

しかし今回発表されたEliza Japanese Llama 2 7bは、かなり良さそうです。まず、このLLMは国産モデルで、GPT-3.5やGPT-4、Anthropic's Claude 2.1などのグローバルモデルと同等のスコアを獲得しているそうです。かなり性能が良いと書かれていますね。
元になっているのは、Meta社が開発したLlama 2の700億パラメータモデルで、それに対して日本語の追加学習とEliza独自の自己学習を行うことで、日本語能力を拡張しているとのことです。
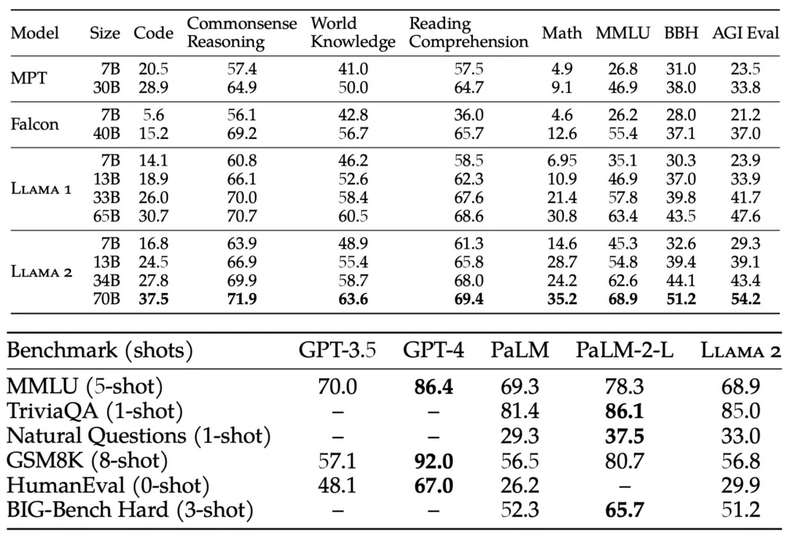
性能評価を見ると、ClaudeやGPT-3.5などと同等レベルになっています。GPT-4は飛び抜けていますが、Gemini、Claudeなどとは近い性能を持っているようですね。今後はAPIとしての提供も予定されているそうです。
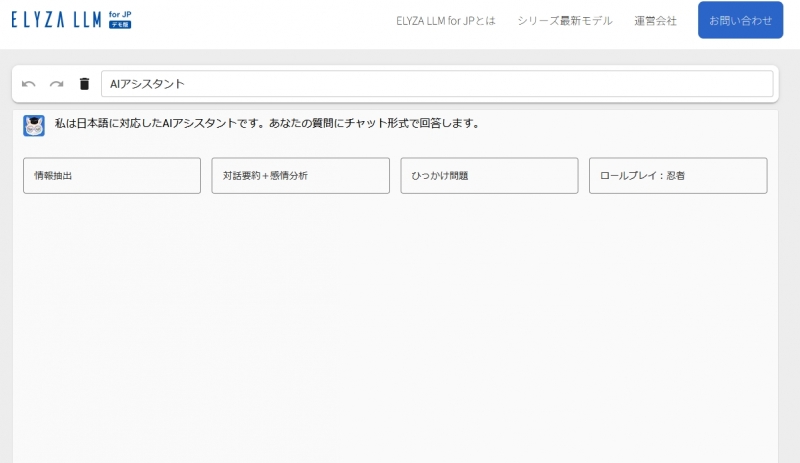
デモを触ってみた印象では、これまでの国産LLMとは違って、ちゃんとした会話ができるし、変な日本語も少ないように感じました。今までは会話が成立しなかったり、すごく変な日本語が返ってくることが多かったので、これは大きな進歩だと思います。
比較として、元のLlama 2でも同じ質問をしてみましたが、Elizaの方が圧倒的に良いですね。Llama 2は日本語がおかしいし、言い回しも不自然です。やはり日本語への追加学習の効果は大きいんだなと実感しました。
ただ、ChatGPTなどの世界トップクラスの言語モデルと比べると、まだまだ改善の余地はありそうです。でも、国産LLMとしては圧倒的に良いんじゃないかなと思います。
リリースされたばかりなので、これからも調整が加えられて、さらに精度が上がっていくことが期待できますね。
これまで国産の言語モデルは何個か出てきていましたが、あまり良いものがありませんでした。グローバルなGPT-4やGemini、Claudeなどと比べると、精度が低くて見劣りしていました。
個人的にはわざわざ国産のAIを使う必要性を感じなかったんですよね。
しかし今回発表されたEliza Japanese Llama 2 7bは、かなり良さそうです。まず、このLLMは国産モデルで、GPT-3.5やGPT-4、Anthropic's Claude 2.1などのグローバルモデルと同等のスコアを獲得しているそうです。かなり性能が良いと書かれていますね。
元になっているのは、Meta社が開発したLlama 2の700億パラメータモデルで、それに対して日本語の追加学習とEliza独自の自己学習を行うことで、日本語能力を拡張しているとのことです。
性能評価を見ると、ClaudeやGPT-3.5などと同等レベルになっています。GPT-4は飛び抜けていますが、Gemini、Claudeなどとは近い性能を持っているようですね。今後はAPIとしての提供も予定されているそうです。
デモを触ってみた印象では、これまでの国産LLMとは違って、ちゃんとした会話ができるし、変な日本語も少ないように感じました。今までは会話が成立しなかったり、すごく変な日本語が返ってくることが多かったので、これは大きな進歩だと思います。
比較として、元のLlama 2でも同じ質問をしてみましたが、Elizaの方が圧倒的に良いですね。Llama 2は日本語がおかしいし、言い回しも不自然です。やはり日本語への追加学習の効果は大きいんだなと実感しました。
ただ、ChatGPTなどの世界トップクラスの言語モデルと比べると、まだまだ改善の余地はありそうです。でも、国産LLMとしては圧倒的に良いんじゃないかなと思います。
リリースされたばかりなので、これからも調整が加えられて、さらに精度が上がっていくことが期待できますね。